Tyler HanI am currently a PhD student in the Paul G. Allen School of Computer Science & Engineering at the University of Washington. I am part of the Robot Learning Lab where I am advised by Byron Boots. I am also an NSF Graduate Research Fellow. Prior to UW, I completed my B.S. in Aerospace Engineering and B.S. in Computer Science at the University of Maryland, College Park. During my undergrad, I worked with Glen Henshaw and Patrick Wensing while at the Naval Research Laboratory in Washington, D.C. Email / GitHub / Google Scholar / LinkedIn / CV (updated Jun 2026) |

|
News
|
|
As we invite robots into places we live and work, my research aims to realize natural robot learning — experiential improvement from signals accessible to or communicable by animals and humans.
I believe these methods will enable more sustainably scalable autonomy for all embodiments, not only those which we can tele-operate, model, or simulate.
|

Online World Modeling Enables Real-World Inverse Reinforcement Learning from ObservationTyler Han, Bat Nemekhbold, Siyang Shen, Rohan Baijal, Richard Ebock, Harine Ravichandran, Sanghun Jung, Kevin Huang, Byron Boots website / code / arXiv Current methods in robot learning are fundamentally bottlenecked by one or more of: hand-designed rewards, simulation modeling, or action supervision (e.g. teleoperation) each requiring significant domain expertise, engineering effort, and robot-operator labor. [...] Towards eliminating these bottlenecks, this work pursues observational learning via Inverse Reinforcement Learning from Observation (IRLfO) in which only access to task observations (e.g. video) is assumed. Due to the challenging setting and limitations of RL methods, IRLfO has thus far remained impractical for real-world robot learning. Here, we present the first IRL method to learn visual manipulation in the real world from scratch, and the first real-world demonstration of positive online transfer across visual manipulation tasks from scratch. In under 40 minutes, MPAIL2 learns pick-and-place from scratch to 82% success, where RL and BC with equal interaction and demonstration budgets reach only 0% and 12% despite their reward and action supervision.
|

Model Predictive Adversarial Imitation Learning for Planning from ObservationTyler Han, Yanda Bao, Bhaumik Mehta, Gabriel Guo, Anubhav Vishwakarma, Emily Kang, Sanghun Jung, Rosario Scalise, Jason Zhou, Bryan Xu, Byron Boots International Conference on Learning Representations (ICLR), 2026 arXiv / OpenReview Best Paper Finalist, Resource-Rational Robot Learning Workshop, CoRL 2025 Humans can often perform a new task after observing a few demonstrations by inferring the underlying intent. [...]For robots, recovering the intent of the demonstrator through a learned reward function can enable more efficient, interpretable, and robust imitation through planning. A common paradigm for learning how to plan-from-demonstration involves first solving for a reward via Inverse Reinforcement Learning (IRL) and then deploying it via Model Predictive Control (MPC). In this work, we unify these two procedures by introducing planning-based Adversarial Imitation Learning, which simultaneously learns a reward and improves a planning-based agent through experience while using observation-only demonstrations. We study advantages of planning-based AIL in generalization, interpretability, robustness, and sample efficiency through experiments in simulated control tasks and real-world navigation from few or single observation-only demonstration.
|
Wheeled Lab: Modern Sim2Real for Low-Cost, Open-Source Wheeled RoboticsTyler Han, Preet Shah, Sidharth Rajagopal, Yanda Bao, Sanghun Jung, Sidharth Talia, Gabriel Guo, Bryan Xu, Bhaumik Mehta, Emma Romig, Rosario Scalise, Byron Boots Conference on Robot Learning (CoRL), 2025 website / code / poster / arXiv / NVIDIA blog / Q&A video / tutorials / WL@UW Reinforcement Learning (RL) has been pivotal in recent robotics milestones and is poised to play a prominent role in the future. [...] However, these advances can rely on proprietary simulators, expensive hardware, and a daunting range of tools and skills. As a result, broader communities are disconnecting from the state-of-the-art; education curricula are poorly equipped to teach indispensable modern robotics skills involving hardware, deployment, and iterative development. To address this gap between the broader and scientific communities, we contribute Wheeled Lab, an ecosystem which integrates accessible, open-source wheeled robots with Isaac Lab, an open-source robot learning and simulation framework, that is widely adopted in the state-of-the-art. To kickstart research and education, this work demonstrates three state-of-the-art zero-shot policies for small-scale RC cars developed through Wheeled Lab: controlled drifting, elevation traversal, and visual navigation. The full stack, from hardware to software, is low-cost and open-source. 
|
Distributional Successor Features Enable Zero-Shot Policy OptimizationChuning Zhu, Xinqi Wang, Tyler Han, Simon Du, Abhishek Gupta Neural Information Processing Systems (NeurIPS), 2024 website / code / arXiv Intelligent agents must be generalists, capable of quickly adapting to various tasks. [...]In reinforcement learning (RL), model-based RL learns a dynamics model of the world, in principle enabling transfer to arbitrary reward functions through planning. However, autoregressive model rollouts suffer from compounding error, making model-based RL ineffective for long-horizon problems. Successor features offer an alternative by modeling a policy’s long-term state occupancy, reducing policy evaluation under new rewards to linear regression. Yet, zero-shot policy optimization for new tasks with successor features can be challenging. This work proposes a novel class of models, i.e., Distributional Successor Features for Zero-Shot Policy Optimization (DiSPOs), that learn a distribution of successor features of a stationary dataset’s behavior policy, along with a policy that acts to realize different successor features achievable within the dataset. By directly modeling long-term outcomes in the dataset, DiSPOs avoid compounding error while enabling a simple scheme for zero-shot policy optimization across reward functions. We present a practical instantiation of DiSPOs using diffusion models and show their efficacy as a new class of transferable models, both theoretically and empirically across various simulated robotics problems. Videos and code: https://weirdlabuw.github.io/dispo/.
|

Model Predictive Control for Aggressive Driving over Uneven TerrainTyler Han, Alex Liu, Anqi Li, Alex Spitzer, Guanya Shi, Byron Boots Robotics: Science & Systems (RSS), 2024 website / arXiv Terrain traversability in unstructured off-road autonomy has traditionally relied on semantic classification, resource-intensive dynamics models, or purely geometry-based methods to predict vehicle-terrain interactions. [...]While inconsequential at low speeds, uneven terrain subjects our full-scale system to safety-critical challenges at operating speeds of 7–10 m/s. This study focuses particularly on uneven terrain such as hills, banks, and ditches. These common high-risk geometries are capable of disabling the vehicle and causing severe passenger injuries if poorly traversed. We introduce a physics-based framework for identifying traversability constraints on terrain dynamics. Using this framework, we derive two fundamental constraints, each with a focus on mitigating rollover and ditch-crossing failures while being fully parallelizable in the sample-based Model Predictive Control (MPC) framework. In addition, we present the design of our planning and control system, which implements our parallelized constraints in MPC and utilizes a low-level controller to meet the demands of our aggressive driving without prior information about the environment and its dynamics. Through real-world experimentation and traversal of hills and ditches, we demonstrate that our approach captures fundamental elements of safe and aggressive autonomy over uneven terrain. Our approach improves upon geometry-based methods by completing comprehensive off-road courses up to 22% faster while maintaining safe operation.
|
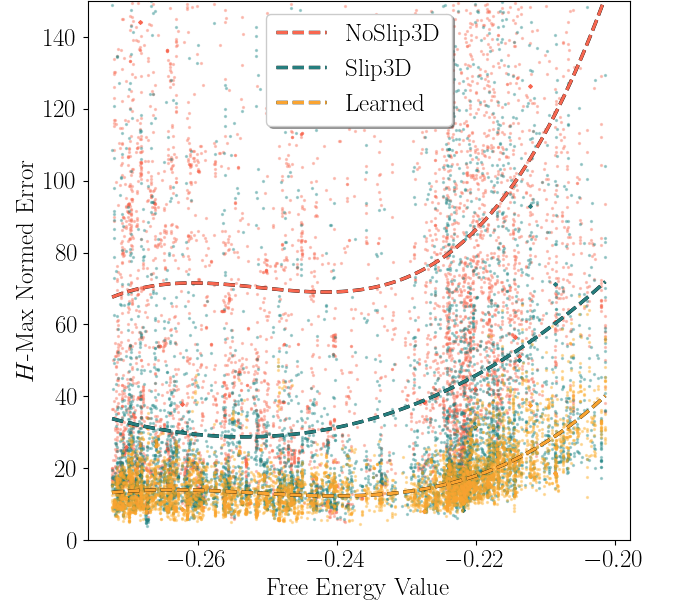
Dynamics Models in the Aggressive Off-Road Driving RegimeTyler Han, Sidharth Talia, Rohan Panicker, Preet Shah, Neel Jawale, Byron Boots Workshop on Resilient Off-Road Autonomy, ICRA, 2024 code / arXiv Current developments in autonomous off-road driving are steadily increasing performance through higher speeds and more challenging, unstructured environments. [...]However, this operating regime subjects the vehicle to larger inertial effects, where consideration of higher-order states is necessary to avoid failures such as rollovers or excessive impact forces. Aggressive driving through Model Predictive Control (MPC) in these conditions requires dynamics models that accurately predict safety-critical information. This work aims to empirically quantify this aggressive operating regime and its effects on the performance of current models. We evaluate three dynamics models of varying complexity on two distinct off-road driving datasets: one simulated and the other real-world. By conditioning trajectory data on higher-order states, we show that model accuracy degrades with aggressiveness and simpler models degrade faster. These models are also validated across datasets, where accuracies over safety-critical states are reported and provide benchmarks for future work.
|
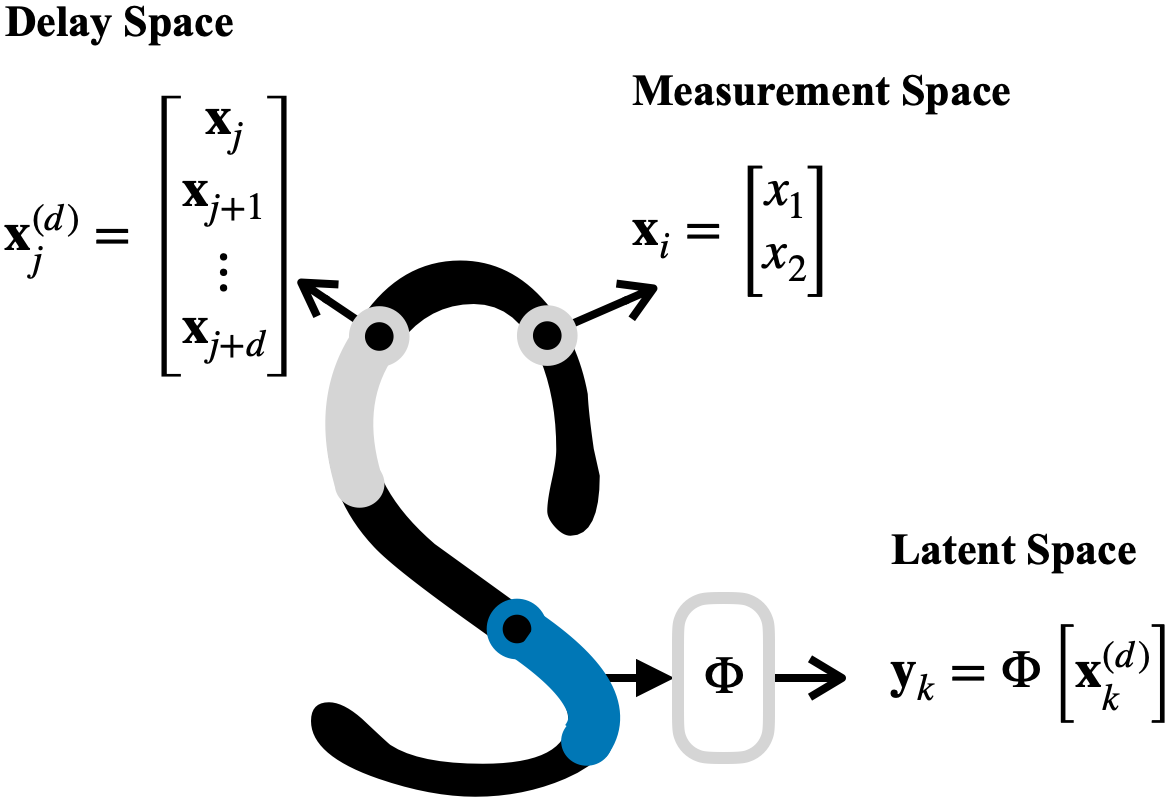
Learning Motor PrimitivesTyler Han, Carl Glen Henshaw arXiv preprint, 2021 arXiv In an undergraduate project, I tackled part of the challenge of teaching robots to perform motor skills from a small number of demonstrations. [...]We proposed a novel approach by joining the theories of Koopman Operators and Dynamic Movement Primitives to Learning from Demonstration. Our approach, named Autoencoder Dynamic Mode Decomposition (aDMD), projects nonlinear dynamical systems into linear latent spaces such that a solution reproduces the desired complex motion. Use of an autoencoder in our approach enables generalizability and scalabil- ity, while the constraint to a linear system attains interpretability. We show results on the LASA Handwriting dataset but with training on only a small fractions of the letters.
|
{kind=link}
|
I believe robotics research is necessarily collaborative, and I'm fortunate to work with and mentor so many talented students. Hands-on experience is invaluable, and I'm grateful to be able to provide these opportunities for students. |
Master's students Siyang Shen
→ Robot Learning Engineer, Humanoid Robot Sahgnhai Co., Ltd.
Siyang Shen
→ Robot Learning Engineer, Humanoid Robot Sahgnhai Co., Ltd.
 Anubhav Vishwakarma
→ Field AI
Anubhav Vishwakarma
→ Field AI
PS
Preet Shah
→ Research Engineer, General Robotics
AL
Alex Liu
→ Software Engineer, Amazon
Undergraduate students Caleb Hsu
Caleb Hsu
 Laura Wang
Laura Wang
 Urvi Rutia
Urvi Rutia
 Bhaumik Mehta
Bhaumik Mehta
YB
Yanda Bao
 Sidharth Rajagopal
Sidharth Rajagopal
AG
Alyssa Giedd
→ Ph.D. at University of Washington
High-school students
VC
Vansh Chhabra
|
|
Advancing automation can also mean displacing workers and those who depend on them as providers. I believe in responsibly broadening access, education, and resources in robotics and AI to support inclusive transitions into a future of automation. |

|
Low-cost Terrain Navigation for Education in End-to-End RoboticsLaura Wang, Caleb Hsu, Byron Boots, Tyler Han CSE 494 capstone project, University of Washington, 2026 poster Eliminates subtle dependency on an inaccessible motion capture system by developing a depth-image based navigation policy in Wheeled Lab. A Sim2Real project in just two quarters! Well done, Laura! |
|
★ …
|
Wheeled LabUniversity of Washington, February 2025 - present website Created an open-source education platform and content for students new to reinforcement
learning in robotics, and advise undergraduate teams beginning in robotics by
mentoring extracurricular Sim2Real projects.
|
|
Last updated June 19, 2026 Forked from Leonid Keselman's Website |